核方法思想
参考阅读:核函数
简单来说,核函数就是我们需要将数据进行高维非线性映射时,减少计算量的一种运算技巧,核函数的选取决定了映射空间的质量,所以有了多核学习,其实就是多种核函数的组合(构成一个加权求和核),通过学习得出一个合适的组合系数
案例1,通过非线性映射函数将原始空间中的线性不可分数据映射到目标空间,从而变得线性可分1:
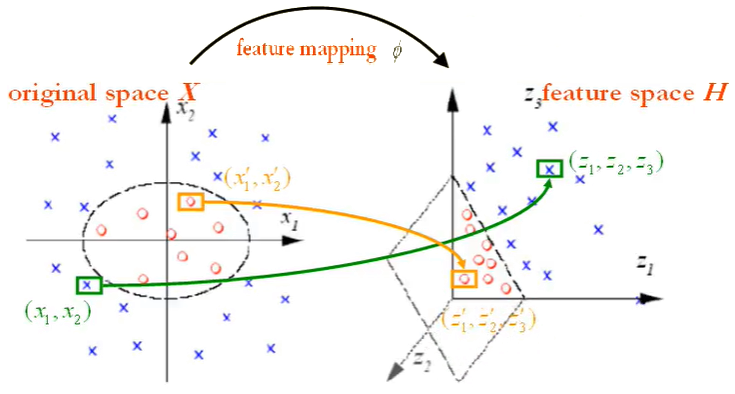
如上图所示,原空间中的红蓝两类样本点(由两个分量构成)可以由一个椭圆曲线非线性地分开,我们可以找到一个非线性映射,使得红蓝样本点在目标空间中可以由一个超平面线性分开,这时,显然空间中的椭圆曲线转变为了中的一条直线,经过它的一个线性超平面可以正确划分两类数据点,到此,你可能会产生一个问题,即这个映射是怎么找到的?
事实上,该问题基本是无解的,我们很难找出确切的映射函数,但是可以将问题进行转化,根据核相关理论,任意非线性映射必然对应有一个核函数,同时给定一个核函数(对应核矩阵需满足有限半正定的条件)就能构建出一个映射空间(指高维希尔伯特空间Hilbert Space),且中的两个样本点内积可以由其在原始空间中的向量表示通过核函数计算得出,即,为向量内积,因此我们要做的是将进行了核扩展的模型目标函数使用核函数表示出来,以避免出现不可解的,那么这个核扩展目标函数该如何定义?以上述二分类为例,给定训练样本集,其中,为类别标签,其在非线性映射空间中的表示为,设在中能够线性划分样本集的超平面为,相应的二分类判别模型为,其中,而根据表示理论,可以由中训练样本的线性组合构成,设为,其中,,于是,由此,问题由求解未知量变为求解未知量,因为通常核函数所对应的高维映射空间维度非常大(甚至是无穷维),远远大于训练样本数,因此引入核函数极大减小了优化代价(未知参数量减少)。接下来的问题就简单了,我们采用Logistic回归构造二分类的目标函数(代价函数),得到,其中,其中为核矩阵,,参数的求解仍可借助感知器通过梯度下降优化算法得到,此时,感知器的输入变为,也就是原本的训练集转变为,变成感知器的权重以及偏置参数
测试阶段,给定测试样本点,其所属类别将由判别模型,其中计算得出
案例2:核PCA